So your dog and cat want a blog.
Instead of referring them to wordpress.com, you offer to set it up for them and foot the $5 it costs to run the most basic of Digital Ocean droplets.
You could get WordPress up and running by choosing an appropriate image or running it in Docker. But that would be too easy. Instead, you set a timer to see if you can set up WordPress along with nginx+PHP+MySQL on a fresh Ubuntu Server 16.04 installation faster than last month when you did it for your hamster.
Leaving such a server unattended would be like leaving your child at a boarding school and never bothering to call and ask how they are. They probably are fine, but something might have happened and you wouldn't know. So it's a good idea to set up some basic monitoring for this server.
Time to set a timer again to bring up an ELK stack for centralized monitoring? I mean, what if your cat's adventure blog takes off? You could but that's like hitting a nail with an ax at this point. Instead, you choose monit as the hammer.
Monit + Slack
Instead of email, I want to receive alerts to my personal Slack team of 1.
I like to use email for communication, not robotic messages. I've noticed that if I get too many alerts or reports in my email inbox, I tend to ignore them.
Slack is free, you can create a team of just one member and there is an app for your phone if you also want push notifications.
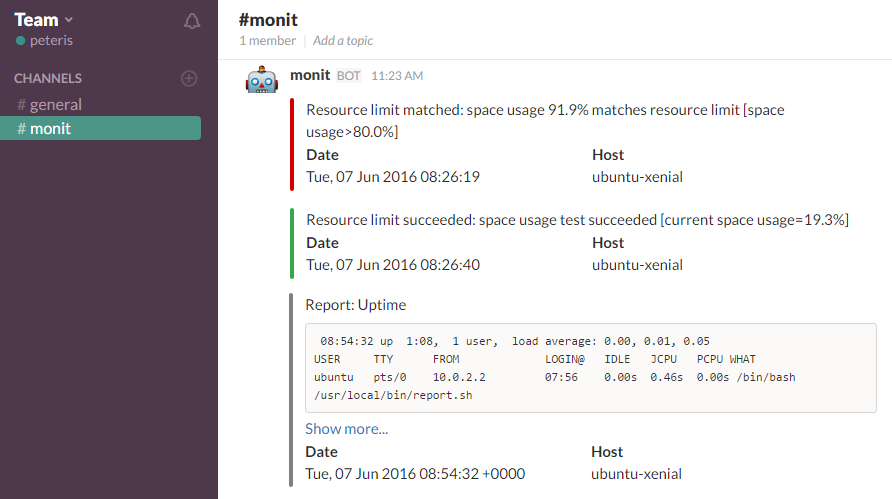
Setup
Monit
On Ubuntu 16.04 you can install it with
sudo apt install monit -y
Make sure that you have a recent version. This tutorial was tested with 5.16.
$ monit --version
This is Monit version 5.16
Monit configuration file is located at /etc/monit/monitrc.
Additional configuration files by default are loaded from
/etc/monit/conf.d/and/etc/monit/conf-enabled/
Like with Apache and nginx configurations on Ubuntu,
/etc/monit/conf-enabled/ is supposed to contain symlinked files from the
/etc/monit/conf-available/ directory.
We are going to use the /etc/monit/conf.d/ directory for our configuration files.
You can verify that your configuration changes do not contain any syntax errors by running
sudo monit -t
If everything is fine, reload the configuration with
sudo monit reload
Slack
- Go to
https://<yourteam>.slack.com/apps/manage/custom-integrations - Click
Incoming WebHooks - Click
Add Configuration - Select an existing channel or create a new one (e.g.
#monit) - you can change it later - Click
Add Incoming WebHooks integration - Copy the
Webhook URL
Let's create a script that uses curl to POST a message to a channel on Slack
sudo tee /usr/local/bin/slack.sh <<\EOF
#!/bin/bash
URL=$(cat /etc/monit/slack-url)
COLOR=${MONIT_COLOR:-$([[ $MONIT_EVENT == *"succeeded"* ]] && echo good || echo danger)}
TEXT=$(echo -e "$MONIT_EVENT: $MONIT_DESCRIPTION" | python3 -c "import json,sys;print(json.dumps(sys.stdin.read()))")
PAYLOAD="{
\"attachments\": [
{
\"text\": $TEXT,
\"color\": \"$COLOR\",
\"mrkdwn_in\": [\"text\"],
\"fields\": [
{ \"title\": \"Date\", \"value\": \"$MONIT_DATE\", \"short\": true },
{ \"title\": \"Host\", \"value\": \"$MONIT_HOST\", \"short\": true }
]
}
]
}"
curl -s -X POST --data-urlencode "payload=$PAYLOAD" $URL
EOF
sudo chmod +x /usr/local/bin/slack.sh
A couple of notes about the command above:
- you can't just do
sudo echo lalala > /file, so I'm usingsudo tee - for multiple lines,
cat << EOF ... EOFis more convenient thanecho -e "lala\nlala" echo lala\nlalawill literally print\ninstead of a new line without the-eflag- I'm using
\EOFinstead ofEOFso that the variables are not replaced with values VAR=${VAR:-lala}will have a default value oflalaif$VARis not set[[ $VAR == *"lala"* ]]is true if$VARcontainslalacurl --data-urlencode "var=value"urlencodes the value for you
Save the Webhook URL that you copied when you created the web hook.
sudo tee /etc/monit/slack-url <<EOF
https://hooks.slack.com/services/XXXXXX/YYYYYY/XyXyY123xxxY
EOF
You can test it that it works by running the script.
MONIT_EVENT="something wrong" MONIT_DESCRIPTION=test MONIT_HOST=`hostname` MONIT_DATE=`date -R` \
/usr/local/bin/slack.sh
WordPress
I have a blog post on how to perform an unattended installation of WordPress on Ubuntu Server. You can also configure WordPress with WP CLI or perhaps using PhantomJS.
Alerts
I believe it is useful take a moment and think about what should be monitored.
The main purpose of this server is to serve the blog contents to its readers. If the blog is down, we are in trouble. If the site is slow, its visitors may leave and that should not happen either.
Instead of monitoring the nginx, php-fpm and mysql processes,
I propose that we check if the server is serving the blog content and whether it is not slow.
I know that it is possible to write rules that will restart nginx if it goes down
but if the nginx process goes down then there is something really wrong
and it should be investigated instead of just restarted.
I really liked this interview with Jeremy Edberg (first paid employee at reddit and now at Netflix) where he said that you should generally monitor the application metrics that matter to your business.
Website is not up
This piece of configuration will periodically check whether the blog is up and running and will send us alerts if it is not.
It will also check that the certificate is valid for at least 10 days.
To prevent way too slow responses, we set a timeout of 1 second.
Lastly, we verify that a string of our choice is found in the first 1 MB of the page. You can also use a regular expression.
BLOGHOST=myblog.com CONTENT="my blog" && \
sudo tee /etc/monit/conf.d/$BLOGHOST <<EOF
check host $BLOGHOST with address $BLOGHOST
if failed
port 80 protocol http request /
with timeout 1 seconds
content = "$CONTENT"
then exec "/usr/local/bin/slack.sh"
else if succeeded then exec "/usr/local/bin/slack.sh"
if failed
port 443 protocol https request /
with timeout 1 seconds
certificate valid > 10 days
content = "$CONTENT"
then exec "/usr/local/bin/slack.sh"
else if succeeded then exec "/usr/local/bin/slack.sh"
EOF
The else if succeeded bit is needed so that you also get an alert that the service is back up.
When the blog reaches more than 2000 monthly visits, you can go and look for external monitoring solutions that will ping your service from all around the world. I am using the free version of monitor.us that checks my websites from Germany and the US and sends a weekly report of average request times and immediate alerts if the website is down.
Running out of disk space
When you've run out of disk space, you will get all kinds of errors. Let's make sure that we are warned in advance when that is about to happen.
sudo tee /etc/monit/conf.d/diskspace <<EOF
check filesystem rootfs with path /
if space usage > 80% then exec "/usr/local/bin/slack.sh" else if succeeded then exec "/usr/local/bin/slack.sh"
EOF
High load
When you're running something as simple as a blog, the system should never run out of memory, start swapping or have a constant high load. If that happens, something is up.
Even when the load is high or too much memory is being used, the website can still be working but it doesn't mean that the sever is healthy. That is why we have this additional check to warn about problems in advance.
sudo tee /etc/monit/conf.d/system <<EOF
check system $HOSTNAME
if memory > 80% for 2 cycles then exec "/usr/local/bin/slack.sh" else if succeeded then exec "/usr/local/bin/slack.sh"
if swap > 10% for 2 cycles then exec "/usr/local/bin/slack.sh" else if succeeded then exec "/usr/local/bin/slack.sh"
if cpu > 80% for 2 cycles then exec "/usr/local/bin/slack.sh" else if succeeded then exec "/usr/local/bin/slack.sh"
if loadavg (5min) > 1 for 2 cycles then exec "/usr/local/bin/slack.sh" else if succeeded then exec "/usr/local/bin/slack.sh"
EOF
Open ports
Let's make sure that there aren't any common open ports that we don't to be open. This may accidentally happen during configuration changes or upgrades.
Unfortunately, the syntax if port 21 then alert else if failed then alert does not work.
But we can use netcat for this. This configuration example also shows how you can use your own scripts with monit.
sudo tee /etc/monit/conf.d/ports <<EOF
check program port21 with path "/bin/sh -c 'echo Port 21 is open ; nc -z $BLOGHOST 21 -w1'" every "5 * * * *"
if status != 1 then exec "/usr/local/bin/slack.sh"
check program port25 with path "/bin/sh -c 'echo Port 25 is open ; nc -z $BLOGHOST 25 -w1'" every "5 * * * *"
if status != 1 then exec "/usr/local/bin/slack.sh"
check program port3306 with path "/bin/sh -c 'echo Port 3306 is open ; nc -z $BLOGHOST 3306 -w1'" every "5 * * * *"
if status != 1 then exec "/usr/local/bin/slack.sh"
EOF
What I like about monit's configuration syntax that it is very readable.
Testing
Don't forget to reload the configuration changes
sudo monit -t
sudo monit reload
Stop the web server and see what happens.
sudo systemctl stop nginx
Create a large file.
sudo fallocate -l 8G /tmp/largefile
Generate high load.
sudo apt install -y stress
stress --cpu `nproc` --timeout 120
Open a port.
sudo nc -l 25
Reports
Alerts should be the way to go. But I also like to receive weekly reports about the server. The reports contain information about uptime, disk space usage, available updates, open ports, etc.
It's useful if you make changes to the server but forget something, you may notice something's wrong when you receive a report.
Since reports are frequent you may suffer from report fatigue and stop paying attention to them, so it's important to summarize them and send them weekly or if that's too much then monthly.
Note that I am using Markdown formatting in the script output.
#!/bin/bash
echo Uptime
echo '```'
w
echo '```'
echo Network
echo '```'
sudo netstat -nlput
echo '```'
echo Disk
echo '```'
df -h
echo '```'
echo Memory
echo '```'
free -h
echo '```'
echo Processes
echo '```'
ps auxf | egrep -v '\[.+\]'
echo '```'
#echo n | sudo apt upgrade # or sudo apt -s upgrade
#find /usr/local -type f -exec md5sum "{}" \; # for example
We can abuse our slack.sh script by using the $MONIT_ variables.
MONIT_EVENT=Report MONIT_DESCRIPTION=`/usr/local/bin/report.sh` \
MONIT_HOST=`hostname` MONIT_DATE=`date -R` MONIT_COLOR="#808080" \
/usr/local/bin/slack.sh
To run it weekly
sudo tee /etc/cron.weekly/slack-report <<\EOF
MONIT_EVENT=Report MONIT_DESCRIPTION=`/usr/local/bin/report.sh` \
MONIT_HOST=`hostname` MONIT_DATE=`date -R` MONIT_COLOR="#808080" \
/usr/local/bin/slack.sh
EOF
sudo chmod +x /etc/cron.weekly/slack-report